Mi az a Web Scraping és hogyan működik a digitális világban
Az adat(Data) és az információ két olyan kifejezés, amelyeket gyakran felcserélhetően használnak, de jelentős különbség van köztük. Például az adatok információbitekre vonatkoznak, de magára az információra nem. Másrészt az információ(Information) olyan adathalmaz, amelyet értelmes módon dolgoznak fel. Az interneten rendelkezésre álló túlnyomó mennyiségű adat révén különböző megközelítések, például a webkaparás(Web Scraping) , a webes (Web Harvesting)adatgyűjtés(Web Data Extraction) vagy a webes adatkinyerés használatosak, hogy megvalósítható és a játékot megváltoztató betekintést nyerjenek az internethasználattal(Internet) kapcsolatban . De mit is jelentenek pontosan az online világban. Lássuk!
Hogyan működik a Web Scraping
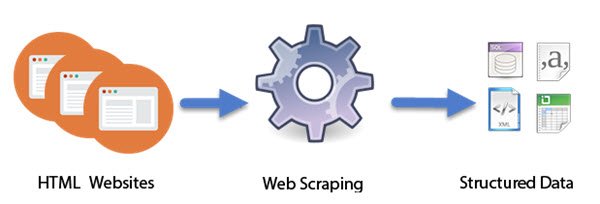
(Computer)Az intelligens robotokként tervezett (Intelligent)számítógépes programok elvégzik a Web Scraping munkáját . Ellentétben a képernyőkaparással, amely csak a képernyőn megjelenő pixeleket másolja, a webes scraping kivonja a HTML -kódot és ezzel együtt az adatbázisban tárolt adatokat. A megközelítés meglehetősen népszerűvé vált. Valójában ez a mai digitális világban az egyik alapvető elsajátítandó készség. Nagyszerű alkalmazásai vannak nagy adatkészletek összeállításában, amelyek alapvetőek az olyan technikákhoz, mint
- Big Data Analytics
- Gépi tanulás
- Mesterséges intelligencia(Artificial Intelligence)
A digitális információk gyors terjedésével a Big Data Web Scraping vagy Web Data Extraction megközelítésen keresztüli elérése sokkal könnyebbé vált . Ennek ellenére a Web Scraping használható olyan digitális vállalkozások számára, amelyek adatgyűjtésre támaszkodnak jogos(Legitimate) és illegitim esetekben egyaránt. Az előbbi a Benevolent Web Scraping példákat(Benevolent Web Scraping Examples) , míg az utóbbi a rosszindulatú webkaparási(Malicious Web Scraping) példákat tartalmazza.
Jóindulatú webkaparási példák
- (Search)A keresőrobotok feltérképezik a webhelyet, elemzik annak tartalmát, hogy bizonyos megállapítások, például a Google alapján rangsoroljanak .
- Ár(Price) -összehasonlító webhelyek, amelyek robotokat telepítenek a termékek árának automatikus lekérésére
- Piackutató(Market) cégek, amelyek kaparókat használnak adatok kinyerésére a közösségi médiából (pl. hangulatelemzéshez, személyes preferenciákhoz stb.).
Példák a rosszindulatú webkaparásra
Az illegális célú webkaparás(Web Scraping) súlyos anyagi veszteségeket okozhat, ha az adatokat a webhelytulajdonosok engedélye nélkül nyerik ki. A rosszindulatú webkaparás(Malicious Web Scraping) két leggyakoribb felhasználási esete az árlekopás és a tartalomlopás.
- Price Scraping – A kaparórobotok(Scraper) ellenőrzik a versengő üzleti adatbázisokat, hogy hozzáférjenek az árinformációkhoz, alákínálják a riválisokat és növeljék az eladásokat.
- Tartalomlopás(Content Theft) – Ez az illegitim tevékenység magában foglalja a célwebhelyről történő nagyszabású tartalomlopást. A tipikus célpontok főként az online termékkatalógusok és a digitális tartalomra támaszkodó webhelyek közé tartoznak az üzleti élet ösztönzése érdekében.
Remélem ez segít!

About the author
Számítástechnikai szakértő vagyok, és iOS-eszközökre szakosodtam. 2009 óta segítek az embereknek, és az Apple termékekkel kapcsolatos tapasztalataim alapján tökéletes ember vagyok, hogy segítsek a technológiai igényeiknek. Képességeim a következők: - iPhone és iPod javítása és frissítése - Apple szoftver telepítése és használata - Segítség az embereknek megtalálni a legjobb alkalmazásokat iPhone-jukhoz és iPodjukhoz - Online projekteken való munka.
Related posts
Nincs internetkapcsolat, de a Webhez csatlakozva jelenik meg
Mi az a Bitcoin, a digitális valuta
Mi történik az online fiókokkal, amikor meghalsz: Digitális vagyonkezelés
Mi az a Dark Web vagy a Deep Web? Hozzáférés és óvintézkedések.
A Digital Detox szedésének előnyei és a kezelés módja
Hogyan lehet módosítani vagy módosítani a WiFi router beállításait?
A legjobb ingyenes internetes adatvédelmi szoftverek és termékek listája a Windows 11/10 rendszerhez
Wi-Fi vs Ethernet: melyiket használja?
Megbízható webhely hozzáadása a Windows 11/10 rendszerben
Mit jelentenek a gyakori HTTP-állapotkód-hibák?
Csoportos gyorstárcsázás Firefoxhoz: fontos internetes webhelyek karnyújtásnyira
Hogyan használjunk megosztott internetkapcsolatot otthon
Az Internet Radio Station ingyenes beállítása Windows PC-n
Összeomolhat az egész internet? A túlzott használat lerombolhatja az internetet?
A Screamer Radio egy megfelelő internetes rádió alkalmazás Windows PC-hez
Hol van most a Mikulás? A Mikulás-követő oldalak segítenek
Mi a 403 tiltott hiba és hogyan javítható?
DDoS elosztott szolgáltatásmegtagadási támadások: védelem, megelőzés
Internetkapcsolat beállítása Windows 11/10 rendszeren
Javítsa ki a Weboldal helyreállítási hibáját az Internet Explorerben